In the ever-expanding world of big data, organizations need powerful tools to process and analyze vast amounts of information efficiently. it is, an open-source distributed computing engine, is at the forefront of this revolution. With its speed, scalability, and real-time processing capabilities, it has become an indispensable tool for data scientists, engineers, and analysts. In this blog, we will dive deep into the architecture, lifecycle, features, and terminologies of Spark, presenting a clear and detailed understanding of its core components.
What is Spark?
It is an open-source distributed computing system designed for processing and analyzing large datasets. Like Hadoop, it operates in a distributed manner, but it distinguishes itself through its in-memory processing capability, making it 100 times faster in-memory and 10 times faster on disk compared to traditional systems.
The Secret Behind Spark’s Lightning Speed
It’s unparalleled speed comes from two main features:
- In-Memory Processing: It processes data directly in memory, reducing the overhead of writing intermediate results to disk.
- Parallel Processing: It’s architecture is designed to run tasks concurrently across multiple nodes, utilizing distributed computing power effectively.
Layered Architecture
At the heart of Spark’s robustness is its well-designed layered architecture, which operates on a master-slave concept. This includes the Driver, Worker, and Cluster Manager components, each fulfilling a distinct role while maintaining loose coupling.
Architecture Components:
Driver Node:
- Acts as the master, initiating the Spark session and overseeing the application lifecycle.
- Translates user code into a Directed Acyclic Graph (DAG) and assigns tasks to worker nodes.
Cluster Manager:
- Manages resources across the cluster and allocates them to worker nodes as required.
- Examples include Standalone, Apache Mesos, or Hadoop YARN.
Worker Nodes:
- Execute tasks assigned by the driver.
- Each worker node contains multiple executors, which process tasks in parallel.
Example Layout:
- Driver
- Cluster Manager
- Worker 1: 64-core processor, 128 GB memory
- Executor 1: 32 GB RAM
- Executor 2: 32 GB RAM
- Executor 3: 32 GB RAM
- Executor 4: 32 GB RAM
- Worker 1: 64-core processor, 128 GB memory
Application Lifecycle
The lifecycle of a Spark application involves a series of steps, ensuring seamless execution:
- Application Submission: The user submits the application.
- Driver Initialization: The driver starts the Spark session.
- DAG Creation: Logical plans are created for tasks.
- Resource Allocation: Task executors request resources from the cluster manager.
- Task Assignment: The driver establishes a connection with workers and assigns tasks.
- Task Execution: Workers execute tasks and return results to the driver.
- Completion: The application ends, and results are returned to the user
Core Features
It’s attributes make it a versatile tool for diverse data processing needs:
- Polyglot Support: Compatible with multiple programming languages, including Scala, Java, Python, R, and SQL.
- Real-Time Processing: Enables near-instantaneous data analytics.
- Fault-Tolerance: Ensures system reliability through data replication and lineage tracking.
- Scalability: Easily handles increasing data and computation loads.
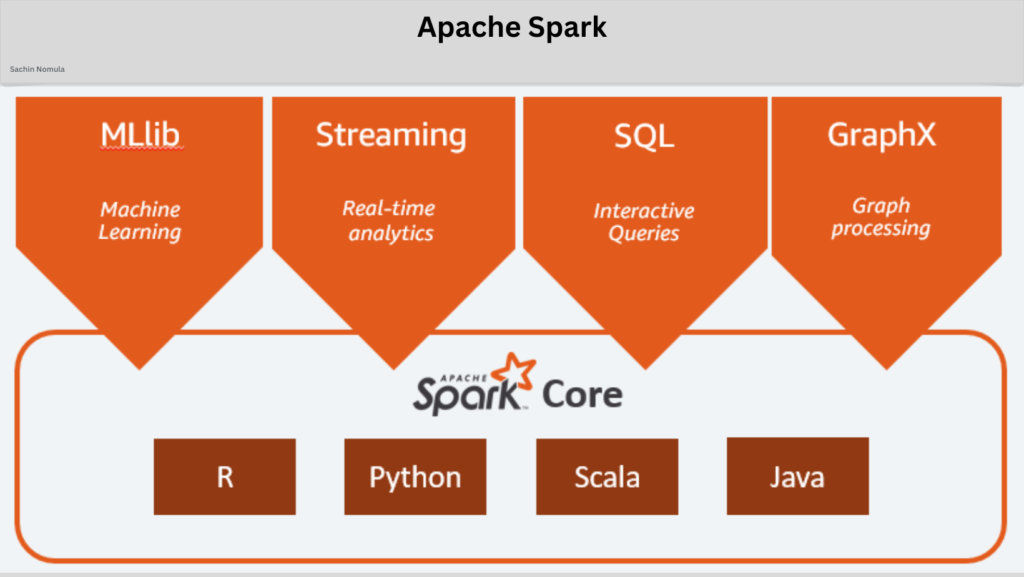
- Rich Libraries: Includes pre-built libraries like SQL, MLib, GraphX, and Spark Streaming.
Terminologies: A Deep Dive
Understanding terminologies is essential for mastering its functionalities:
Driver and Worker Process:
- Both are Java Virtual Machine (JVM) processes.
- A single worker node can host multiple executors, each running in its own JVM.
Application:
- Represents the user’s program submitted for execution.
- Can consist of a single command or a complex combination of notebooks.
Jobs, Stages, and Tasks:
- Job: Created when the driver converts application code into an executable unit.
- Stage: Jobs are divided into stages based on data shuffling requirements.
- Tasks: Stages are broken into tasks, each processing a single partition.
Transformation:
- Modifies the input Resilient Distributed Dataset (RDD) to create a new RDD.
- Evaluated lazily until an action is invoked.
Action:
- Triggers execution by processing data and producing results.
RDD:
- Spark’s fundamental data structure, distributed across nodes and stored in partitions.
Libraries and Supported Languages
Ecosystem includes a range of powerful libraries:
- Spark SQL: Enables structured data processing.
- Spark Streaming: Processes real-time data streams.
- MLLib: A machine learning library for scalable computations.
- GraphX: For graph processing and graph-parallel computation.
Supported programming languages include Scala, Java, Python, R, and SQL, making it accessible to a broad audience.
Memory Management
Efficient memory usage is key to it’s performance. Its memory architecture is divided into:
On-Heap Memory:
- Managed by the JVM and divided into:
- Unified Memory: 60% of heap memory, split evenly between storage and execution.
- User Memory: 40% of heap memory.
- Reserved Memory: A small portion reserved for internal Spark processes.
- Managed by the JVM and divided into:
Off-Heap Memory:
- Managed outside the JVM by the operating system, offering additional flexibility
A Code Example
Here’s a simple example of using Spark to filter and group data from a CSV file
from pyspark.sql import SparkSession
# Initialize Spark Session
spark = SparkSession.builder.appName(“SparkExample”).getOrCreate()
# Read CSV file
df = spark.read.format(“csv”).option(“header”, True).load(“/Sales/2007-2008.csv”)
# Filter data for a specific county
df1 = df.filter(df[“County”] == “KINGS”)
# Group data by year and count
df2 = df1.groupBy(“Year”).count()
# Show results
df2.show()
It is revolutionizes how we process and analyze big data, offering unmatched speed, scalability, and versatility. Its well-designed architecture, fault-tolerance, and rich libraries make it a go-to choice for a wide range of data applications. By understanding it’s core components and features, you can harness its full potential to drive innovation and insights in your projects.