In the world of machine learning, building a model that performs well on unseen data is the ultimate goal. However, achieving this balance can be challenging due to two common issues: overfitting and underfitting. These problems impact the model’s ability to generalize, leading to suboptimal performance. In this blog, we will explore overfitting and underfitting in detail, along with their causes, symptoms, and remedies, to help you create robust machine learning models
What is Overfitting?
Overfitting occurs when a model learns the training data too well, including its noise and irrelevant patterns. While this results in high accuracy on the training data, the model fails to generalize and performs poorly on new, unseen data. Overfitting is typically the result of excessive model complexity or insufficient data.
Causes of Overfitting
High model complexity: Excessive parameters or layers enable the model to memorize training data.
Limited training data: Small datasets increase the risk of memorizing noise.
Irrelevant features: Including features that do not contribute meaningfully to predictions.
Long training duration: Prolonged training without monitoring can lead to memorization of noise.
Symptoms of Overfitting
High training accuracy but low validation/test accuracy: A clear gap between training and validation performance.
Poor generalization: The model’s predictions degrade significantly on unseen data.
How to Address Overfitting
Simplify the Model
Reduce the number of parameters, layers, or features used.
Regularization
Use techniques like L1 (Lasso) or L2 (Ridge) regularization to penalize large weights and simplify the model.
Data Augmentation
Increase training data diversity by applying transformations, such as rotations, flips, or noise injection for image data.
Cross-Validation
Employ K-fold cross-validation to evaluate the model’s performance on different subsets of the data.
Early Stopping
Monitor the validation loss during training and halt when it stops improving.
Dropout (for Neural Networks)
Randomly deactivate neurons during training to prevent over-reliance on specific features.
Ensemble Methods
Combine predictions from multiple models to leverage their strengths and reduce variance.
What is Underfitting?
It happens when a model is too simple to capture the underlying patterns in the data. As a result, it performs poorly on both training and validation datasets. it typically occurs due to overly simplistic assumptions or insufficient training.
Causes of Underfitting
Low model complexity: The model lacks the capacity to capture intricate patterns in the data.
High regularization: Excessive constraints prevent the model from learning adequately.
Short training time: Insufficient epochs or iterations.
Inadequate features: Missing or poorly engineered features fail to represent the data properly.
Symptoms of Underfitting
Low training and validation accuracy: The model struggles to fit even the training data.
Inability to capture trends: Failure to identify the underlying structure of the data.
How to Address Underfitting
Increase Model Complexity
Use more complex models with additional parameters, layers, or features.
Feature Engineering
Create or transform features to better represent the data and its relationships.
Reduce Regularization
Lower the strength of regularization to allow the model to capture patterns.
Increase Training Time
Train the model for more epochs or iterations to improve learning.
Hyperparameter Tuning
Adjust learning rates, batch sizes, and other parameters for better performance.
Balancing Overfitting and Underfitting
Striking the right balance between overfitting and underfitting is crucial for building models that generalize well to unseen data. Here are some strategies to achieve this balance:
Train with Sufficient Data
Use as much high-quality, relevant data as possible to improve generalization.
Choose the Right Model
Select a model whose complexity aligns with the problem’s requirements.
Use Validation Data
Monitor performance on a separate validation set to ensure the model generalizes well.
Perform Hyperparameter Optimization
Use techniques like grid search or random search to fine-tune hyperparameters.
Leverage Ensemble Methods
Combine the strengths of multiple models to reduce errors and improve robustness.
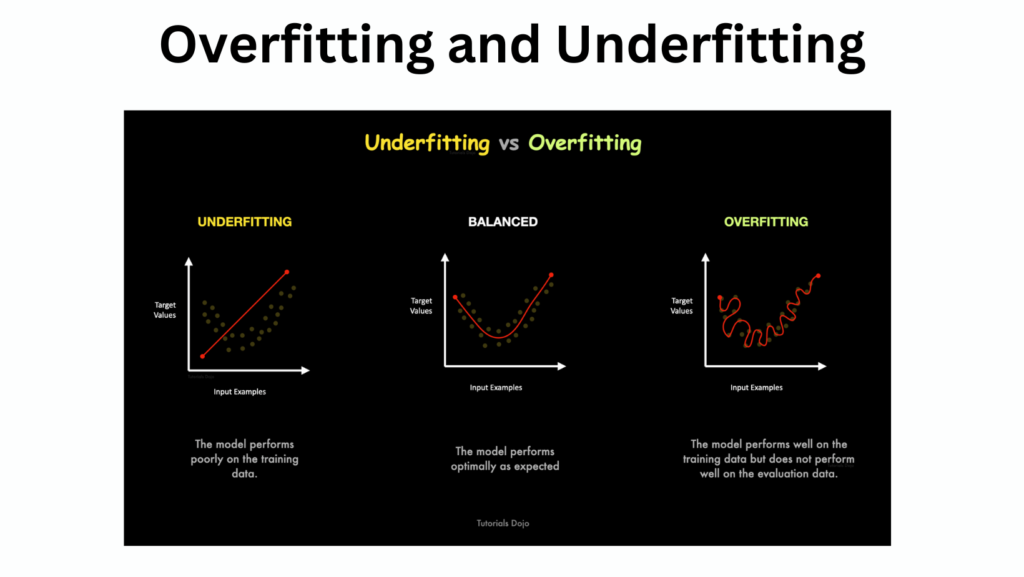
Visualizing
To better understand these concepts, imagine fitting a curve to a dataset:
Overfitting: The curve passes through every data point, capturing noise instead of the underlying pattern.
Underfitting: The curve is too simplistic, failing to capture the true relationships in the data.
Good Fit: The curve captures the underlying trend while ignoring noise, ensuring good performance on unseen data.
Both are critical challenges in machine learning, but they can be mitigated with proper strategies. By understanding their causes and employing the remedies discussed above, you can build models that generalize well and deliver accurate predictions. Whether you’re a beginner or an experienced practitioner, addressing these issues effectively is a vital step toward creating robust and reliable machine learning systems.