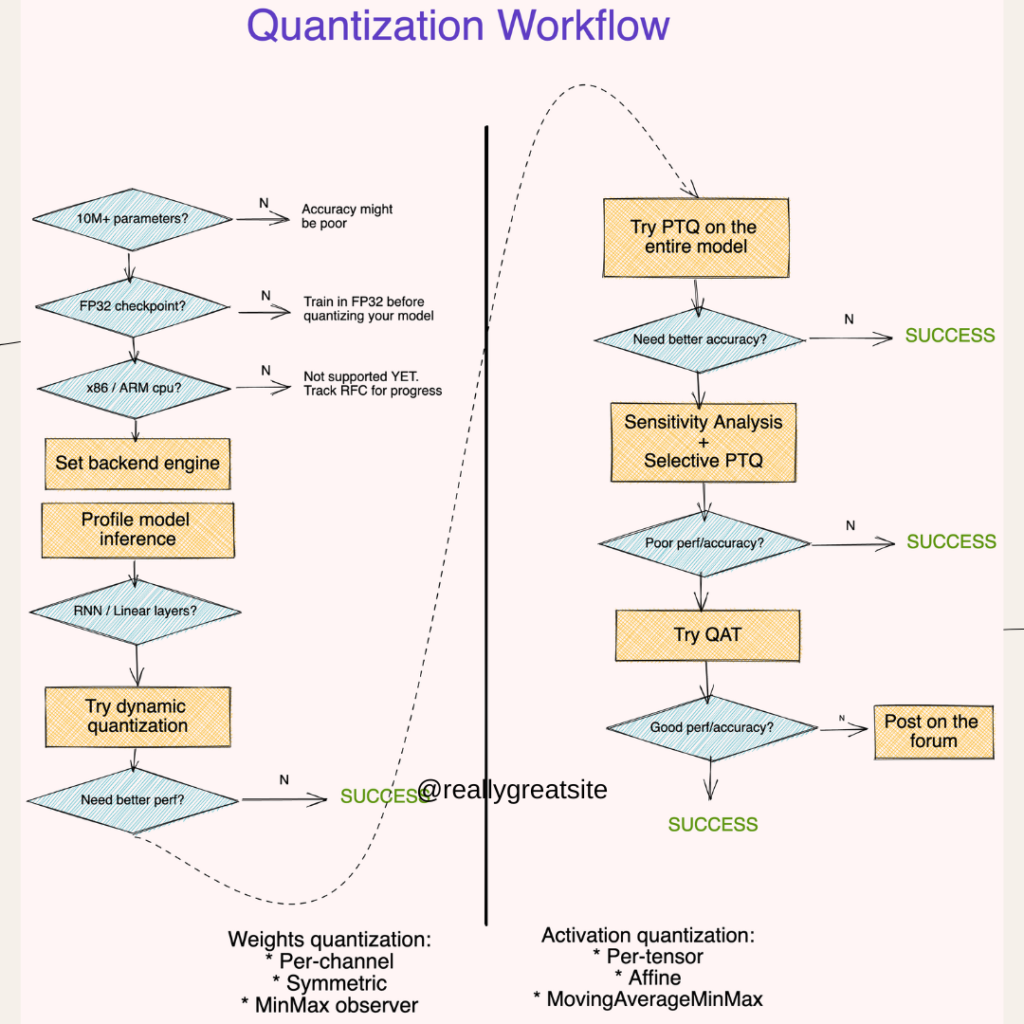
Dynamic quantization is a powerful technique used to optimize deep learning models for inference, particularly for memory-constrained environments or real-time applications. By converting model weights from floating-point (FP32) to 8-bit integers (INT8), dynamic quantization can significantly reduce memory usage and enhance inference speed, while maintaining a reasonable level of accuracy. In this blog, we’ll explore how dynamic quantization can be applied to LSTM-based word language models and discuss its benefits, implementation, and use cases.
What is Dynamic Quantization?
Dynamic quantization is a post-training optimization technique where the weights of a model are stored in INT8 format. During inference, activations are dynamically quantized to INT8, computations are performed in INT8, and the results are dequantized back to FP32. This process strikes a balance between computational efficiency and precision.
Key Benefits:
Reduced Model Size: INT8 weights require significantly less storage compared to FP32 weights.
Faster Inference: Modern CPUs are optimized for INT8 computations, resulting in lower latency.
Minimal Accuracy Loss: Suitable for tasks where slight precision loss is acceptable.
How to Apply Dynamic Quantization to an LSTM Word Language Model
Let’s walk through the steps to apply dynamic quantization to an LSTM-based word language model.
Step 1: Train the Model
Train a word language model using standard techniques. The model typically includes an embedding layer, an LSTM layer, and a linear output layer. Save the trained model in FP32 format.
Here’s an example of a simple LSTM model:
import torch
import torch.nn as nn
class LSTMWordModel(nn.Module):
def __init__(self, vocab_size, embed_size, hidden_size, num_layers):
super(LSTMWordModel, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_size)
self.lstm = nn.LSTM(embed_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, vocab_size)
def forward(self, x):
x = self.embedding(x)
out, _ = self.lstm(x)
out = self.fc(out)
return out
# Train the model and save its state
model = LSTMWordModel(vocab_size=5000, embed_size=256, hidden_size=512, num_layers=2)
# Assume training is completed
torch.save(model.state_dict(), ‘lstm_model.pth’)
Step 2: Load the Model
Load the trained model for quantization.
# Load the model
model = LSTMWordModel(vocab_size=5000, embed_size=256, hidden_size=512, num_layers=2)
model.load_state_dict(torch.load(‘lstm_model.pth’))
model.eval()
Step 3: Apply Dynamic Quantization
Quantize the model using PyTorch’s torch.quantization.quantize_dynamic function.
# Apply dynamic quantization
quantized_model = torch.quantization.quantize_dynamic(
model, # The original model
{nn.LSTM, nn.Linear}, # Layers to quantize
dtype=torch.qint8 # Quantization type
)
Step 4: Evaluate the Quantized Model
Test the quantized model to ensure it performs adequately. Compare its size, speed, and accuracy with the original FP32 model.
Evaluate Size:
def print_model_size(model):
torch.save(model.state_dict(), “temp.p”)
size = os.path.getsize(“temp.p”) / 1e6 # Size in MB
os.remove(“temp.p”)
print(f”Model size: {size:.2f} MB”)
print_model_size(model) # Original model
print_model_size(quantized_model) # Quantized model
Evaluate Speed:
import time
def measure_inference_time(model, input_data):
start_time = time.time()
with torch.no_grad():
for _ in range(100):
_ = model(input_data)
elapsed_time = time.time() – start_time
print(f”Elapsed time: {elapsed_time:.2f} seconds”)
input_data = torch.randint(0, 5000, (1, 10)) # Batch size 1, sequence length 10
measure_inference_time(model, input_data) # Original model
measure_inference_time(quantized_model, input_data) # Quantized model
Evaluate Accuracy: Compare the perplexity or another accuracy metric before and after quantization.
Real-World Applications
Dynamic quantization is particularly useful in the following scenarios:
Resource-Constrained Environments: Deploy LSTM models on devices with limited memory and computational power, such as mobile phones or embedded systems.
Real-Time Applications: Use in applications where low latency is critical, like chatbots or real-time translation.
Batch Processing: Optimize inference speed for processing large datasets in production.
Best Practices for Dynamic Quantization
Quantize Specific Layers: Focus on layers with the most computation, such as
nn.LSTMandnn.Linear, for maximum impact.Test for Accuracy: Ensure the quantized model’s accuracy is acceptable for the task.
Profile Performance: Use profiling tools to measure the trade-offs between size, speed, and accuracy.
Use Quantization-Aware Training (QAT): For highly sensitive tasks, consider QAT to achieve better accuracy.
FAQs
1. How does dynamic quantization differ from static quantization?
Dynamic quantization quantizes weights offline and quantizes activations during inference, while static quantization precomputes both weights and activations.
2. Can dynamic quantization be applied to GPUs?
It is primarily optimized for CPUs. It is not as effective on GPUs, which excel with FP32 computations.
3. What are the limitations of dynamic quantization?
The method is less effective for models with complex activation functions or high sensitivity to small numerical changes.
4. How much memory can I save with dynamic quantization?
Savings depend on the model architecture but typically range from 2x to 4x compared to FP32 models.
5. Does it work with all PyTorch layers?
No, it is best suited for
nn.Linearandnn.LSTM. Other layers may require alternative quantization techniques.
Conclusion
Dynamic quantization is a straightforward and effective technique to optimize LSTM-based word language models for production. By reducing model size and increasing inference speed, it enables deployment in environments with limited resources while maintaining a high level of performance. By following the steps outlined in this guide, you can integrate dynamic quantization into your deep learning workflows and unlock the full potential of your models.
Would you like to explore more advanced quantization techniques or need help optimizing your specific use case? Let us know in the comments!