In today’s fast-paced digital landscape, the ability to process and transmit data efficiently is critical for businesses. Apache Kafka has emerged as a robust distributed messaging platform, leveraging a publish-subscribe mechanism to stream records in real-time. Originally developed by LinkedIn, Kafka was later donated to the Apache Software Foundation and has since become an open-source solution widely adopted by enterprises like LinkedIn, Airbnb, Netflix, Uber, and Walmart.
What is Apache Kafka?
Apache kafka is a distributed event-streaming platform designed to handle high-throughput and low-latency data streaming. It functions as a messaging system in a distributed environment, allowing various services to communicate with each other seamlessly.
Messaging System Overview
A messaging system transfers data from one application to another, enabling applications to focus on processing the data without worrying about transmission complexities. There are two primary types of messaging systems:
Point-to-Point Messaging System:
Messages are stored in a queue.
Each message is consumed by only one receiver.
The receiver can process the message without time constraints.
Once processed, the receiver sends an acknowledgment to the sender.
Publish-Subscribe Messaging System:
Messages are stored in topics and can be consumed by multiple subscribers.
There is a time dependency for consumers to process the messages.
Subscribers do not send acknowledgments back to the publisher.
It follows the publish-subscribe model, where messages are categorized into topics, and consumers can subscribe to these topics to receive messages in real-time
Kafka’s Architecture
Apache Kafka consists of several key components:
Topics
A topic is a logical feed name used to categorize messages. It functions like a database table where records (or messages) are stored. Topics are crucial to Kafka’s functionality:
Each topic is uniquely identified by its name.
Producers publish messages to topics, and consumers read messages from them.
Topics can have multiple partitions for scalability and performance.
Partitions
Topics are divided into partitions to enable distributed processing:
Messages in a partition are immutable and stored in a sequential order.
Each message has a unique offset within its partition.
Partitions allow Kafka to distribute data across multiple brokers for parallel processing.
Producers
Producers are applications that publish messages to topics. They use the Producer API to:
Write data to all partitions of a topic.
Target specific partitions for message delivery.
Consumers
Consumers are applications that subscribe to topics and consume messages. They:
Use the Consumer API to read messages.
Can belong to consumer groups, ensuring load balancing and parallel processing.
Brokers
Brokers are Kafka servers responsible for storing and managing messages. A Kafka cluster consists of multiple brokers that communicate with each other to:
Maintain consumer offsets.
Deliver messages to the appropriate consumers.
Ensure fault tolerance and scalability.
Kafka Cluster
Apache kafka cluster is a collection of brokers working together to provide a distributed messaging platform. Kafka clusters offer:
Horizontal scalability by adding new brokers without downtime.
Fault tolerance by replicating partitions across brokers.
Zookeeper
Zookeeper is a centralized service used to manage Kafka clusters. It:
Maintains metadata information such as broker configurations and health status.
Coordinates broker tasks and elects the controller node.
Functions as a key-value store for Kafka metadata.
Kafka’s Key Features
Scalability: Apache kafka supports horizontal scaling by adding brokers to existing clusters without downtime.
Fault Tolerance: By replicating partitions across brokers, Kafka ensures high availability even during failures.
Durability: Kafka’s distributed commit log ensures messages are written to disk as quickly as possible, making it highly durable.
Performance: Kafka delivers high throughput for both producing and consuming messages.
No Data Loss: Proper configurations ensure data integrity and prevent loss.
Zero Downtime: Kafka’s architecture ensures seamless operation during maintenance or scaling activities.
Reliability: Kafka’s combination of features makes it a reliable choice for critical systems.
Kafka APIs
Apache kafka provides several APIs to interact with its system:
Producer API: Allows applications to publish messages to topics.
Consumer API: Enables applications to subscribe to topics and consume messages.
Streams API: Facilitates processing streams of data within Kafka.
Connector API: Simplifies the integration of Kafka with external systems such as databases and monitoring tools.
Admin API: Provides tools to manage and monitor Kafka clusters.
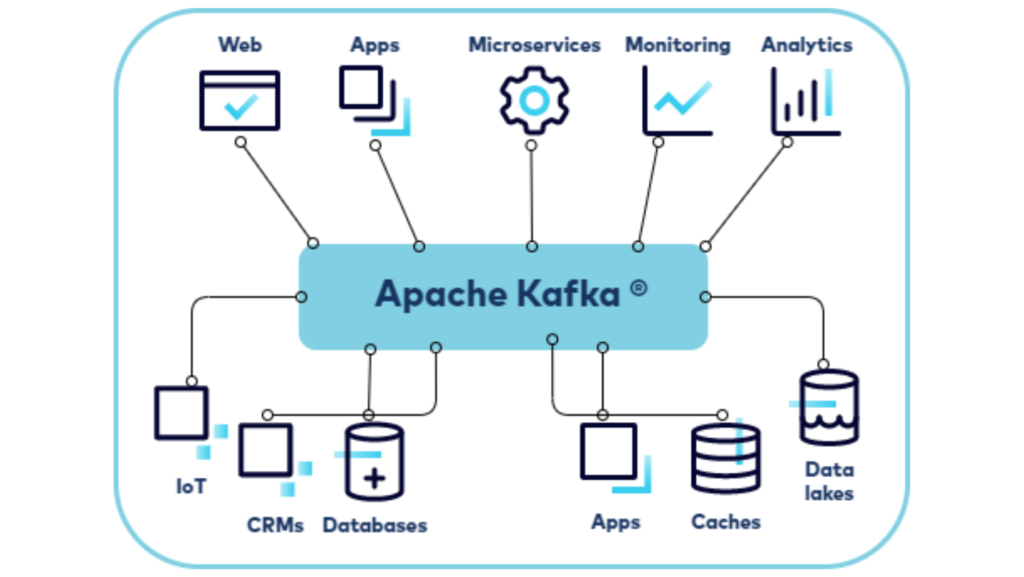
Use Cases
Apache kafka is versatility makes it suitable for various applications:
Real-Time Analytics: Process and analyze data streams in real time for insights.
Log Aggregation: Collect and manage log data from multiple sources for monitoring and debugging.
Event Sourcing: Maintain a history of events to reconstruct system states.
Stream Processing: Process and transform data streams for advanced analytics.
Messaging: Enable communication between microservices in distributed architectures.
Apache kafka is a powerful and flexible distributed messaging platform, offering unparalleled scalability, reliability, and performance. With its publish-subscribe model, It supports a wide range of real-time applications, from analytics to event processing. By leveraging its robust architecture and extensive APIs, businesses can build efficient and resilient systems to handle today’s demanding data requirements.
Whether you’re a developer, data engineer, or enterprise architect, understanding Apache kafka is core concepts and features can unlock new opportunities for innovation and efficiency in data-driven environments.