Apache Spark offers three powerful APIs for data processing and analytics: RDD (Resilient Distributed Dataset), DataFrame, and Dataset. While these APIs provide similar functionalities in terms of data processing and delivering output, they differ significantly in handling data, performance optimization, and user convenience. This blog will explore the journey, similarities, differences, and memory management aspects of these APIs.
The Evolution of Spark APIs
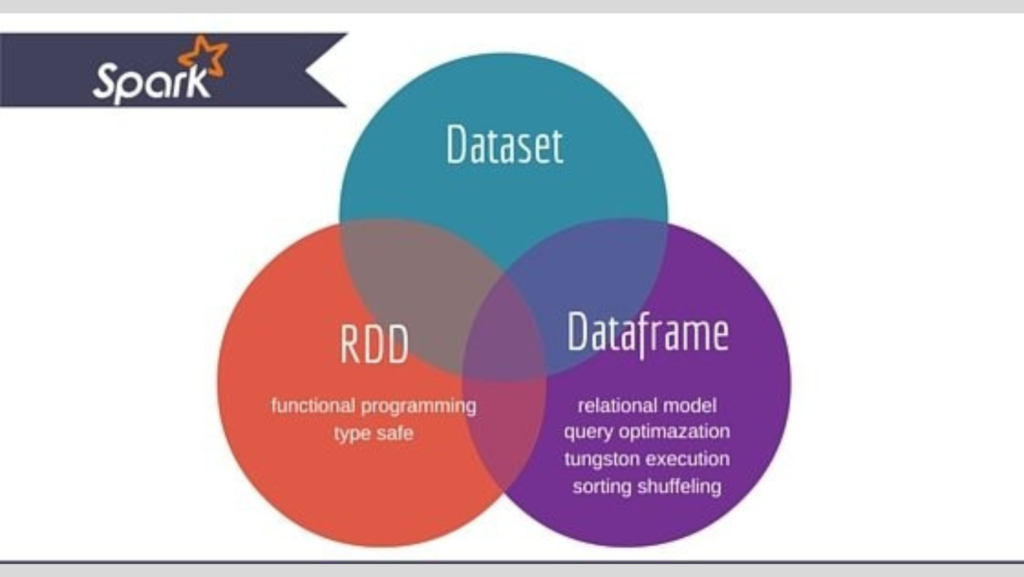
1. RDD (Resilient Distributed Dataset)
Introduced in Spark 1.0 (2011).
Provides low-level, functional programming control over data.
2. DataFrame
Introduced in Spark 1.3 (2013).
Offers a high-level abstraction with a schema, enabling SQL-style operations.
3. Dataset
Introduced in Spark 1.6 (2015).
Combines the best features of RDD and DataFrame: strong type safety and optimization.
Key Features and Differences
| Feature | RDD | DataFrame | Dataset |
|---|---|---|---|
| Programming Style | Functional (OOPs style API) | Declarative (SQL style API) | Functional (DOP style API) |
| Schema | Not applicable | Schema-based | Schema-based |
| Type Safety | Strong | Less | Strong |
| Optimization | No optimization | Catalyst Optimizer | Catalyst Optimizer |
| Language Support | Java, Scala, Python | Java, Scala, Python, R | Scala, Java |
| Serialization | Unavoidable | Avoidable (off-heap used) | Avoidable (via encoders) |
| Garbage Collection | Affects performance | Mitigated by off-heap storage | Mitigated by off-heap storage |
Choosing the Right API
Use RDD for complex data manipulations requiring low-level control.
Use DataFrame for large-scale SQL-based operations.
Use Dataset for operations requiring type safety and optimization.
Similarities Between RDD, DataFrame, and Dataset
Fault Tolerance: All three APIs ensure fault tolerance by recomputing lost data partitions.
Distributed in Nature: Data is processed across multiple nodes.
In-memory Parallel Processing: Optimized for fast processing by keeping data in memory.
Immutability: Transformations create new objects rather than modifying existing ones.
Lazy Evaluation: Operations are not executed immediately but are built into a Directed Acyclic Graph (DAG).
Transformations and Actions
Transformations
Transformations are operations that transform data from one form to another without triggering execution. Examples include:
Filter: Filters data based on a condition.
Union: Combines two datasets.
Example:
DF2 = DF1.filter(DF1.emp_id == 200)
Actions
Actions trigger the execution of transformations and return results or save output to storage. Examples include:
Count: Returns the number of records.
Collect: Gathers all data to the driver.
Save: Writes data to a storage layer.
Example:
DF2.write.save(“output_path”)
Narrow vs. Wide Transformations
Narrow Transformation
Data from a single partition is used by a single output partition.
Example: Filter
Wide Transformation
Data from multiple partitions is shuffled across the cluster.
Example: Group By
Code Example:
DF2 = DF1.groupBy(“Dept”).count()
Memory Management: On-Heap vs. Off-Heap
Spark’s memory management is critical for performance. It uses both on-heap and off-heap memory.
On-Heap Memory
Advantages:
Automatic memory management.
Efficient for small datasets.
Disadvantages:
Relies on JVM Garbage Collection (GC), which can degrade performance.
Stores data as Java objects (deserialized).
Off-Heap Memory
Advantages:
Avoids GC overhead by directly managing memory via the operating system.
Stores data as serialized byte arrays, reducing JVM memory usage.
Suitable for large datasets exceeding heap memory.
Disadvantages:
Requires manual memory management.
Slower than on-heap but faster than disk I/O.
Enabling Off-Heap Memory in Spark:
spark.memory.offHeap.use = true
spark.memory.offHeap.size = 4g
Executor Memory Model
Each worker node in Spark contains executors, which manage memory for tasks.
Memory Components
Reserved Memory: Used for Spark’s internal operations (e.g., 300MB).
User Memory: For user-defined data structures.
Execution Memory: For shuffle operations, joins, and aggregations.
Storage Memory: For caching data.
Unified memory model:
Total memory = Execution Memory (50%) + Storage Memory (50%)
Example Setup:
Worker memory: 16GB
Executor memory: 10GB (6GB managed by OS as off-heap memory)
Lazy Evaluation and DAG
Spark’s lazy evaluation builds a DAG of transformations, allowing it to optimize execution.
Example DAG Workflow
Source DataFrame (DF1)
Transformation: Filter
Transformation: Group By
Action: Save
Code Example:
DF2 = DF1.filter(DF1.emp_id == 200)
DF3 = DF2.groupBy(“Dept”).count()
DF3.write.save(“output_path”)
Conclusion
Understanding the differences between RDD, DataFrame, and Dataset is crucial for effectively using Spark. While RDD offers fine-grained control, DataFrame and Dataset bring schema-based processing and optimizations. Choosing the right API depends on the specific use case, balancing performance, type safety, and ease of use.
By leveraging Spark’s memory management techniques and DAG optimization, developers can process large-scale data efficiently, unlocking the full potential of distributed computing.