Model versioning is critical for ensuring reproducibility, collaboration, and effective deployment in machine learning (ML). Here’s how to do it effectively:
Why Model Versioning Matters
- Traceability: Tracks changes in models, datasets, and code.
- Reproducibility: Enables the recreation of past results.
- Collaboration: Streamlines teamwork and reduces conflicts.
- Rollback Capability: Simplifies reverting to a stable version when issues arise.
Components to Version
To ensure complete traceability, version the following:
- Model Code: The source code defining the model and its architecture.
- Hyperparameters: Training parameters such as learning rate or batch size.
- Datasets: Training and testing datasets, including preprocessing steps.
- Artifacts: Trained model weights, saved in formats like
.h5or.pkl. - Dependencies: Environment configurations (e.g., Python libraries, frameworks).
Steps to Implement Model Versioning
Adopt a Versioning Strategy
- Use Semantic Versioning:
MAJOR.MINOR.PATCH.- MAJOR: Breaking changes (e.g., architectural redesign).
- MINOR: Backward-compatible additions (e.g., a new feature).
- PATCH: Bug fixes or minor tweaks.
- Use Semantic Versioning:
Use Experiment Tracking Tools Tools like MLflow, Weights & Biases, or Neptune.ai allow:
- Logging hyperparameters and metrics.
- Comparing experiment results.
- Storing associated model artifacts.
Maintain a Model Registry A model registry organizes and tracks models by version. Example tools:
- MLflow Model Registry: Tracks models, metadata, and lifecycle stages.
- AWS SageMaker Model Registry: Integrates with the AWS ecosystem.
- DVC: Manages models and datasets alongside version control for code.
Leverage Version Control for Code and Data
- Use Git for tracking code changes.
- Use DVC or cloud storage (e.g., AWS S3, Google Cloud Storage) for large data and artifacts.
Log Metadata Record key details for each version:
- Dataset Version: Source, size, preprocessing.
- Performance Metrics: Accuracy, precision, recall, etc.
- Training Environment: Libraries, framework versions, hardware.
Automate with CI/CD Pipelines
- Automate model testing and evaluation before deployment.
- Deploy models only if they meet predefined performance thresholds.
Monitor Deployed Models Track live performance metrics (e.g., accuracy drift) and retrain if needed.
Plan for Rollbacks
- Retain older versions for backup.
- Label models with statuses like Active, Archived, or Deprecated.
Best Practices for Model Versioning
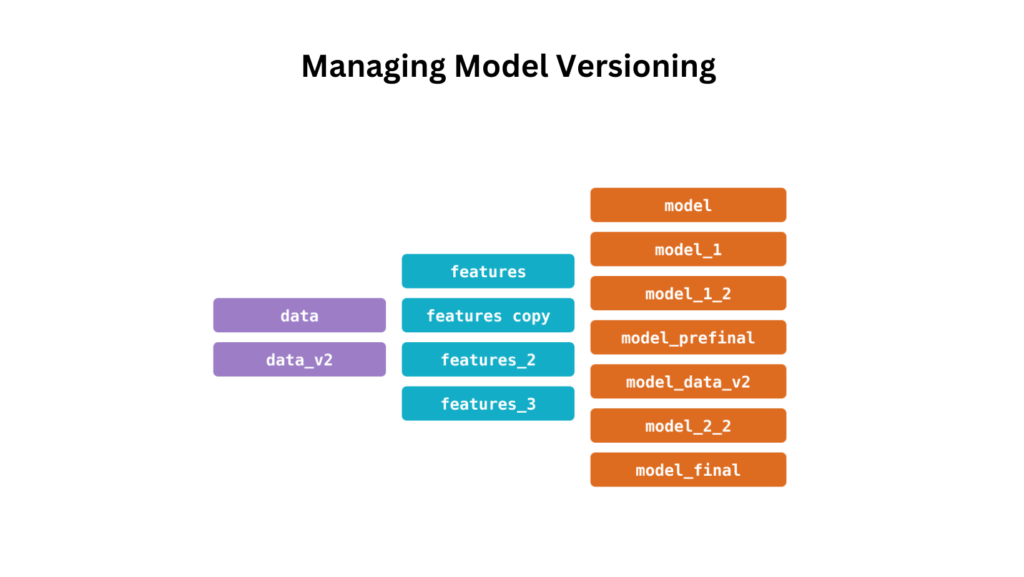
- Use descriptive tags (e.g.,
model_v1.2_performance_85). - Maintain detailed documentation of each version.
- Automate backups of model artifacts and metadata.
- Monitor and compare deployed versions continuously.
Popular Tools for Model Versioning
| Tool | Purpose | Features |
|---|
| Git | Version control for code. | Branching, tagging, and merging. |
| DVC | Data and model versioning. | Integrates with Git; tracks large files. |
| MLflow | Experiment tracking and model lifecycle. | Logs metrics, artifacts, and versions. |
| Weights & Biases | Experiment tracking and collaboration. | Visual dashboards and integrations. |
| AWS SageMaker | Model registry and deployment. | Lifecycle management for AWS ML models. |
Effective model versioning is essential for scalable and reliable machine learning systems. By adopting structured practices and leveraging robust tools, teams can achieve reproducibility, streamlined collaboration, and efficient model management.
FAQ
1. What is model versioning in machine learning?
Model versioning is the process of tracking and managing changes to machine learning models, datasets, and related components throughout their lifecycle. It ensures reproducibility, collaboration, and traceability of experiments and deployments.
2. Why is model versioning important?
- Reproducibility: Ensures you can replicate results using the same code, data, and configurations.
- Rollback Capability: Allows reverting to earlier versions when newer models fail in production.
- Collaboration: Facilitates teamwork by enabling multiple developers to work on different versions simultaneously.
- Experiment Tracking: Helps in comparing models and identifying the best-performing version.
3. What tools are commonly used for model versioning?
Some widely used tools include:
- Git: For version control of code.
- MLflow: For logging experiments, metrics, and managing the model lifecycle.
- DVC: For tracking datasets and model artifacts along with code.
- Weights & Biases: For experiment tracking and collaboration.
- AWS SageMaker Model Registry: For managing models on AWS.
4. What are the best practices for naming model versions?
- Use Semantic Versioning:
MAJOR.MINOR.PATCH(e.g.,v1.2.3). - Include descriptive tags: For example,
model_v1.0_accuracy85. - Record timestamps: Combine versioning with dates (e.g.,
v1_2024-11-29).