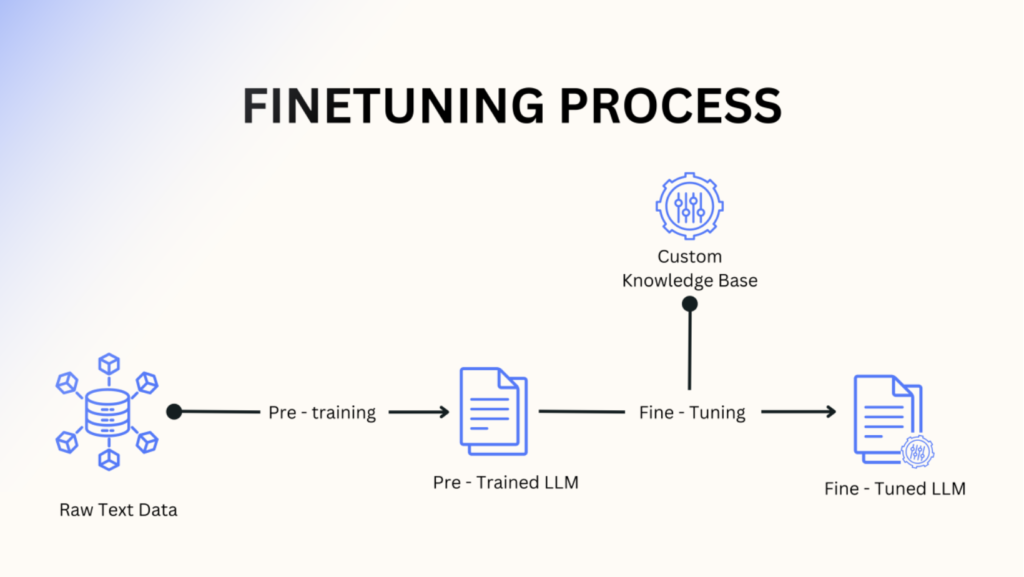
Fine-tuning is essential for adapting large language models (LLMs) like GPT and BERT to perform specialized tasks. While general-purpose models excel at handling a variety of text, they often need refinement to be effective in niche areas such as legal analysis, medical research, or customer service. In this article, we’ll explore popular fine-tuning techniques, their advantages, and practical tips to maximize results.
What is Fine-Tuning?
Fine-tuning refers to customizing a pre-trained model to improve its performance on specific tasks or domains. By tailoring a general-purpose model, you can boost its accuracy in areas such as sentiment analysis, legal document summarization, or customer support automation. This process bridges the gap between the broad capabilities of LLMs and the specialized precision required for specific use cases.
Essential Techniques for Fine-Tuning LLMs
1. Full Fine-Tuning in LLMs
In full fine-tuning, all parameters in the model are adjusted using task-specific data.
-
- When to Use: This technique is ideal for small-scale models or cases where fine control over outputs is essential.
-
- Challenges: It requires high computational power and large memory resources. There’s also a risk of overfitting, where the model memorizes training data instead of learning patterns.
2. Low-Rank Adaptation (LoRA) in LLMs
LoRA inserts low-rank matrices into the model, updating only a subset of parameters to save memory and compute resources.
-
- Use Case: Useful in resource-constrained environments, such as fine-tuning models on a limited GPU.
-
- Benefits: Reduces training time and memory requirements while maintaining accuracy.
3. Quantized Low-Rank Adaptation (QLoRA) in LLMs
QLoRA builds on LoRA by quantizing weights to 4-bit precision, which further reduces memory usage
-
- When to Use: Ideal for fine-tuning on a single GPU without compromising performance.
-
- Benefits: Efficient and cost-effective, QLoRA allows faster fine-tuning without requiring powerful hardware.
4. Feature Extraction (Repurposing)
This technique involves freezing most of the model’s layers and only updating the final layers to perform specific tasks.
-
- Example: In models like BERT, the pre-trained layers understand grammar and context, so you only need to adjust the final layers for tasks like question answering.
-
- Benefit:Speeds up fine-tuning by leveraging existing knowledge from the pre-trained model
5. Adapter Layers
Adapter layers are small, trainable modules added between the model’s original layers. During fine-tuning, only these adapters are trained, leaving the core parameters untouched
-
- Benefit: Perfect for multi-task fine-tuning, as it avoids retraining the entire model.
-
- When to Use: Ideal when you need to adapt a model to multiple tasks with minimal compute overhead.
6. Prompt Tuning
Instead of modifying the model, prompt tuning uses carefully crafted text or numeric inputs to guide the model’s behavior
-
- Benefit:Low-cost solution, as model parameters remain unchanged.
-
- Use Case: Works well for few-shot learning scenarios, where the goal is to get the right output without extensive re-training.
7. Instruction-Tuning
Instruction-tuning involves training the model using datasets with specific instructions, such as “Summarize this text” or “Translate to Spanish.”
-
- Benefit: Increases the model’s ability to follow instructions accurately across different tasks.
-
- Best Use Case: Highly beneficial for chatbots and conversational AI systems.
8. Fine-Tuning with Reinforcement Learning (RLHF)
RLHF (Reinforcement Learning with Human Feedback) combines it with reinforcement learning, where human feedback helps guide the model’s behavior.
-
- When to Use: Essential for aligning LLMs to human values, such as reducing harmful or biased outputs.
-
- Challenges: Requires a reward model and a careful balance between automation and human oversight.
Choosing the Right Technique
| Scenario | Recommended Technique |
| Limited compute and memory resources | LoRA, Adapter Layers, Prefix-Tuning |
| Task requires complete model adaptation | Full Fine-Tuning |
| Task requires following complex instructions | Instruction-Tuning |
| Preference-based behavior control | RLHF |
| Adapting for multiple tasks | Multi-Task Fine-Tuning |
Best Practices for Fine-Tuning
-
- Use High-Quality Data: The performance of a fine-tuned model depends heavily on the relevance and diversity of the dataset.
-
- Prevent Overfitting: Apply early stopping techniques or regularization to avoid the model memorizing the training data.
-
- Monitor Performance: Regularly evaluate the model across multiple metrics to ensure it generalizes well to new inputs.
-
- Optimize Learning Rates: A low learning rate helps prevent catastrophic forgetting of the original knowledge.
-
- Use Checkpoints: Save intermediate versions of the model to avoid data loss during training.
Conclusion
Fine-tuning unlocks the full potential of LLMs by tailoring them for specific domains and tasks. Techniques like LoRA and QLoRA make it possible to fine-tune models efficiently, even in resource-limited environments. Meanwhile, RLHF ensures that models align with human preferences, making them safer and more reliable. For scenarios requiring minimal retraining, prompt tuning provides a cost-effective solution, while instruction-tuning enhances the accuracy of conversational systems.
By selecting the right fine-tuning method, you can develop highly specialized models that deliver accurate, relevant, and resource-efficient results across industries..
Frequently Asked Questions (FAQs)
-
- What is the difference between LoRA and QLoRA?
- LoRA updates selected parameters using low-rank matrices, while QLoRA compresses weights to 4-bit precision for better memory efficiency.
-
-
Why is fine-tuning necessary?
It is crucial because:
- Domain Adaptation: Pre-trained models may not perform optimally in niche areas like legal, medical, or scientific domains.
- Task Specialization: Specific tasks like summarization, classification, or translation require additional customization.
- Data Sensitivity: Fine-tuning can address specific organizational data needs without retraining an entire model from scratch.
- What is the difference between LoRA and QLoRA?