In the world of machine learning, XGBoost has emerged as a powerful and reliable tool, dominating competitions and finding its place in production systems across industries. Known for its exceptional speed, scalability, and accuracy, XGBoost has become a go-to choice for data scientists and engineers alike. This blog will take you through the history of XGBoost, its key features, and the reasons behind its outstanding performance.
The History of XGBoost
Early Days and Development
XGBoost, short for “Extreme Gradient Boosting,” was first introduced in 2011 by Tianqi Chen. The tool was designed to address the limitations of existing gradient boosting algorithms, focusing on scalability and efficiency while maintaining high accuracy.
The core idea behind it was to improve the gradient boosting framework by making it more robust and flexible. This vision led to innovations in regularized learning objectives, sparsity-aware algorithms, and parallel processing capabilities. These features quickly made XGBoost a standout tool in the machine learning landscape.
Rise to Prominence
it gained significant attention when it started dominating Kaggle competitions between 2011 and 2019. The algorithm’s ability to handle large datasets and deliver robust performance made it a favorite among data science practitioners. With over 29 competition wins attributed to its use, it solidified its reputation as a tool of choice for high-performance machine learning tasks.
Open Source and Community Growth
One of the key milestones in it’s journey was its release as an open-source project. This decision spurred rapid adoption and contributions from a growing community of developers and researchers. The community-driven development ensured that XGBoost remained at the cutting edge of machine learning technology, integrating new features and enhancements to meet evolving demands.
Key Features of XGBoost
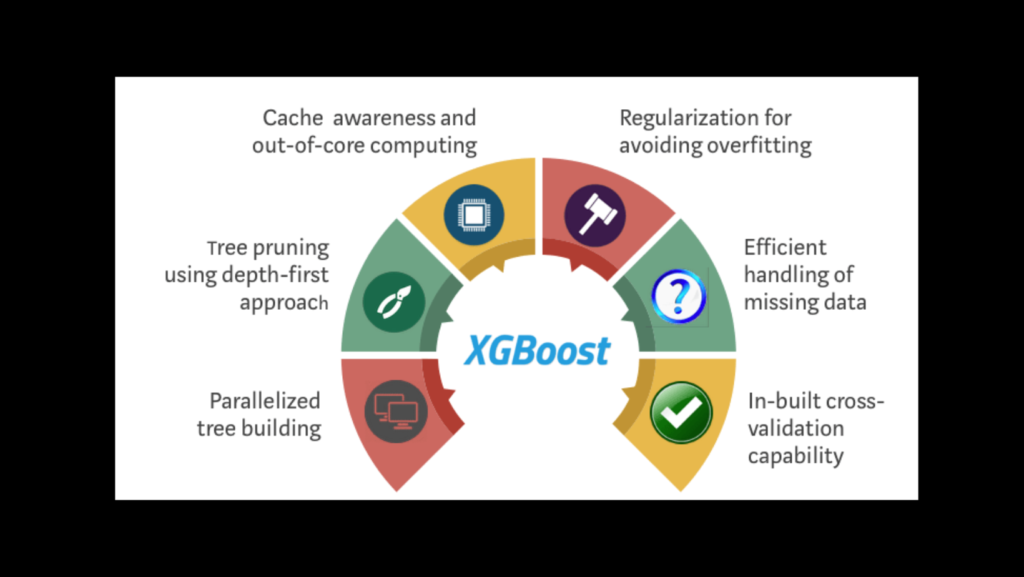
XGBoost’s success can be attributed to its rich set of features, which cater to the diverse needs of machine learning practitioners. Let’s explore these features in detail:
1. Performance
It is designed for speed and efficiency, leveraging advanced techniques to maximize performance:
Parallel Processing: XGBoost supports parallel computation, significantly reducing training times.
Optimized Data Structures: It uses block structure for storing data, enhancing memory access and computation speed.
Cache Awareness: The algorithm optimizes memory usage, making it suitable for large-scale datasets.
Out-of-Core Computing: XGBoost can handle datasets larger than the available memory by using disk space efficiently.
Distributed Computing: It supports distributed training, enabling the use of multiple machines for large datasets.
GPU Support: With GPU acceleration, XGBoost delivers faster training for computationally intensive tasks.
2. Flexibility
Flexibility is another hallmark. It provides:
Support for Various Problems: XGBoost can handle regression, classification, and ranking tasks with ease.
Cross-Platform Compatibility: It works seamlessly across multiple platforms, including Windows, Linux, and macOS.
Integration with Other Tools: XGBoost integrates well with popular libraries and frameworks like Scikit-learn, Dask, Spark, and Hadoop.
Multiple Language APIs: It offers APIs for Python, R, Java, Scala, Julia, and more, catering to a broad range of users.
3. Advanced Features for Model Building
Regularized Learning Objectives: it includes L1 and L2 regularization, helping to prevent overfitting.
Handling Missing Values: The algorithm intelligently manages missing data, ensuring robust performance.
Sparsity-Aware Split Finding: It efficiently handles sparse datasets by identifying meaningful splits.
Efficient Split Finding: Techniques like weighted quantile sketch and approximate tree learning improve split computation.
Tree Pruning: XGBoost employs a “max depth” or “min child weight” strategy to prune trees, reducing unnecessary complexity.
4. Explainability and Workflow Integration
SHAP Values: XGBoost supports SHAP (SHapley Additive exPlanations) values for interpreting model predictions.
Workflow Tools: Integration with workflow management tools like Airflow simplifies deployment and automation.
Why XGBoost Outperforms Other Algorithms
Regularized Learning Objectives
it’s use of regularized learning objectives helps in controlling model complexity, improving generalization, and reducing the risk of overfitting. This is a critical factor in achieving high accuracy on both training and test datasets.
Handling Missing Data
Unlike many algorithms that require preprocessing to handle missing values, it inherently manages them by learning optimal split directions. This feature not only simplifies data preparation but also ensures robustness in real-world applications.
Sparsity Awareness
In practical scenarios, datasets often contain sparse features. it’s sparsity-aware split finding mechanism efficiently handles such datasets, ensuring meaningful splits without unnecessary computation.
Scalability
With support for distributed computing and GPU acceleration, XGBoost can scale to handle massive datasets. This scalability makes it an ideal choice for big data applications, where traditional algorithms struggle to keep up.
Community Support
XGBoost’s active community ensures continuous updates, bug fixes, and the addition of new features. This dynamic development environment keeps XGBoost at the forefront of machine learning innovation.
Applications of XGBoost
it’s versatility and performance make it suitable for a wide range of applications:
Finance: Risk modeling, fraud detection, and credit scoring.
Healthcare: Disease prediction, patient outcome analysis, and personalized medicine.
E-commerce: Customer segmentation, recommendation systems, and demand forecasting.
Marketing: Predictive analytics, customer churn prediction, and campaign optimization.
Government: Tax evasion detection, census analysis, and policy impact assessment.
it has revolutionized the field of machine learning by offering a powerful, scalable, and flexible solution for a variety of predictive modeling tasks. Its rich feature set, combined with an active community and continuous innovation, ensures its relevance in the ever-evolving landscape of machine learning.
Whether you are a data science enthusiast or a seasoned practitioner, mastering XGBoost can significantly enhance your ability to tackle complex problems and deliver impactful solutions. Dive into its documentation, experiment with its features, and join the community to unlock the full potential of this remarkable tool.